





はじめに
言語知能システム研究チームは、言語に基づくヒトの知能の工学的実現を目指しています。
ヒトの知は言語によっていると考えられることから、ヒトの脳を創るに際しては、言語的アプローチも必要です。現状では言語のような脳の高次機能については、神経細胞やそのシステムレベルから解明することは難しく、言語的アプローチはトップダウン的なものにならざるを得ません。しかし、脳が創り出した言語システムを脳の外で、詳しく観察できるという支えがあります。
言語的アプローチの基礎は言語理論です。私のチームでは選択体系機能言語学を用いています。そして、日本語のシステムの計算論的モデルと、モデルに基づいたテクスト理解/生成のアルゴリズムを実装し、言語に基づく脳型の情報処理環境を構築しようとしています。また、この研究を通じて、言語を受容する神経アーキテクチュアについての知見が得られるだろうという期待もあります。
言語理論
選択体系機能言語学(SFL:SystemicFunctional Linguistics)はイギリスのハリデー(現シドニー大学名誉教授)によって創始された言語学です。チームのアドバイザーでもあるハリデーは、現実のコンテクストにおいて使用される言語の意味から出発します。チョムスキーが、遺伝的に継承され脳に内在するという普遍文法から出発するのと対照的です。
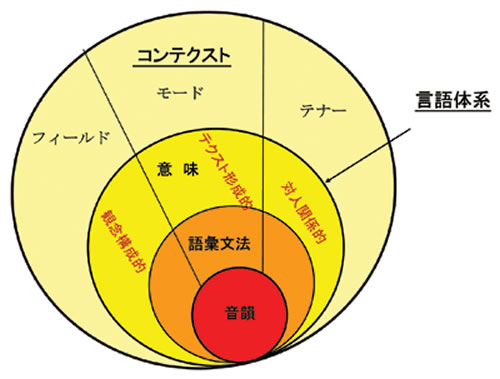
SFLは言語システムを4つの階層、音韻/書記、語彙文法、意味、コンテクストに分け、また、言語の機能を、観念構成的、対人関係的、テクスト形成的の3つに分けて記述します。たとえば、観念構成的意味は考えを表すときの意味です。図1に示すように他の層も3つの機能に分けられ、コンテクストもフィールド(言語の場)、テナー(参与者)、モード(言語の媒体)によって特徴づけられます。
言語的アプローチにおいて重要なのは、言葉を理解し話すためには、脳の中に何がなければならないかという問いと、あるべき言語システムを表現する方法です。文法と語彙があれば話せる訳ではありません。SFLでは、文法をコンテクストにおける意味を音韻によって表現するための仕組みと考えています。
実際、ヒトの言語の進化の歴史においても、音声器官の進化は別にして、コンテクストは最初からあり、次にコンテクストの中で表現すべき意味が生じ、その意味が複雑になるにつれ、適切に表現するための文法が創られたのは間違いないところでしょう。
失語症研究からの知見(山鳥 1997)によれば、右利きの人の場合、大脳右半球がコンテクスト理解に関わり、左半球のブローカ/ウェルニッケ領野を含む中央の領域が文法に関わり、その外側を同心円状に囲む領域が意味理解に関わっているそうです。また、ヒト以外の動物も右脳をコンテクスト監視に用いていると言われます。
計算論的モデル
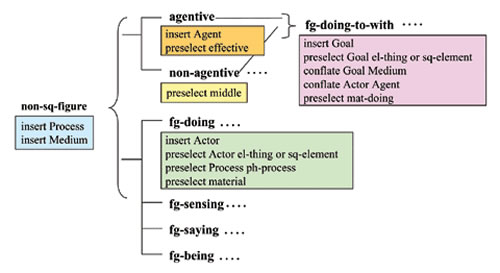
言語システムを計算機に実装するには、計算論的モデルが必要となり、チームではSFLに基づくモデルをセミオティクベースと呼ぶデータベースとして構築しました。セミオティックベースは表現ベース(音韻/書記)、語彙文法ベース、意味ベースとコンテクストベースから構成されています。図2は意味ベースの内容の一部です。SFLでは、意味システムを意味特徴という要素から成るものとして表現し、図2のようなツリー状の構造をシステムネットワークと呼んでいます。ネットワークのノードが意味特徴で、右へ行くに従い、細かい特徴が表れます。意味特徴をもつシステムネットワークは、意味を表現するメタ言語です。言語の意味を言語で記述すると、記述自体の意味が問われますから、メタ言語という概念は重要です。脳内の言語システムのモデル表現にも、当然メタ言語を必要とします。意味のシステムネットワークにおいて、四角の中の記述は具現規則と言って、この意味特徴をテクストの中に具現するためには、どんな語彙文法特徴を用いればよいかを示しています。語彙文法システムも同様に語彙文法特徴を用いて記述されます。このように、SFLでは意味と語彙文法は密接な関係にあります。コンテクストベースには、フィールド、テナー、モードの記述以外に、状況のタイプや知識、コーパス(テクストの実例)がデータとして格納されています。この他、語彙項目の汎用辞書があります。
さらに、セミオティックベースを用いて、テクスト理解と生成の計算論的モデルを構築しました。あるコンテクストにおいて、話したい内容を意味システムの中の意味特徴を選択的に指定することで表現し、語彙文法システムと語彙項目を用いて、テクストとして具現する過程が生成です。生成が意味からテクストへの前向きの過程だとすれば、理解はちょうどその逆の、テクストから意味への後ろ向きの過程で、形態素解析/係り受解析という前処理をした後、語彙文法解析、意味解析、概念解析の順に行われます。
言語コンピューティング
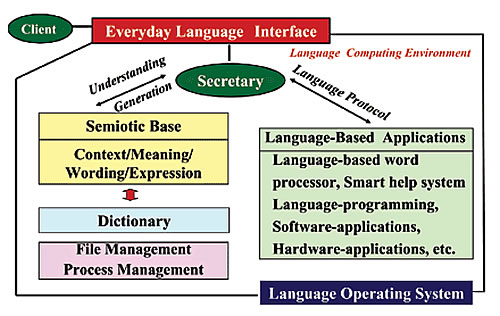
言語と理解/生成の計算論的モデルの機能を検証するために、日常言語コンピューティングというパラダイムを提唱して、言語によるコンピューティング環境を実現しようとしています。アイデアは、ヒトの脳と同じようにコンピュータを言語化することによって、コンピュータ上のすべての情報処理を言語により管理・実行しようとするものです。図3はそのシステム構成を示します。具体的には、言語ワープロ、スマートヘルプシステム、言語プログラミングシステムのプロトタイプを構築し、実装してみました。これらは、言語モデルに基く理解/生成の機能を利用して、ユーザーがコンピュータと日常言語で対話しつつ、コンピュータを自由に使えるようにしようとするものです。例えば、言語ワープロはユーザーの音声指示に基づいて、ドキュメントを作成できますが、ユーザーは、「暑中見舞いを書きたい」、「文字をもっと強調したい」、「夏らしい絵を入れたい」などと指示することができます。これらのシステムは、去る6月の国内の人工知能学会でデモンストレーションを行い、好評を博しました。
脳の言語機能
脳の言語機能には、言語システムの記憶以外に、言語処理、言語利用、言語学習の3つがあると考えられます。言語処理とは理解とです。現在は、言語処理機能を計算機上に実現するための計算論的モデルを構築した段階ですが、次のステップにおいては、神経埋め込むための神経計算論的モデルを構築する必要があります。
言語利用としては、言語による認識、言語による思考、言語による経験の解釈などがあるでしょうが、ヒトの脳を創るためには、思考の計算論的モデルを構築しなければなりません。言語によるコンピューティングの研究は、このために役立つと思われます。
言語学習は研究計画に入っていません。しかし、言語学習のモデルを作るとき、まず必要なことは学習すべき対象を定義することは、話すためには、語彙項目はもちろん階層的言語システムとともに、理解/生成の仕方も学ばなければならないと考えています。
