




One day, while discussing a variety issues, Dr. Okihide Hikosaka, then at Juntendo University and now at National Institute of Health, showed some puzzling experimental results to me (Hiro Nakahara). Our efforts to clarify these findings led to a recent publication that, roughly stated, suggests that the right motivation can promote learning.
The basal ganglia play important roles in learning and complex motor control and have an abundance of dopamine (DA) neurons. DA neural responses are believed to indicate the difference between predicted reward and the actual reward, called“reward prediction error”. Many have noted that this prediction error shares characteristics with an error signal (or learning signal) called TD error that is associated with a computer algorithm called the temporal difference model (TD model). This is a type of algorithm for reinforcement learning. This powerful algorithm is used in computer games and machine controllers. Therefore, given the known important role of the basal ganglia in motor control, DA neuron activity is attracting increasing attention.
Yet a lot remains to be investigated before an understanding of detailed mechanism of DA activities in reward prediction can be developed. For example, there are many forms of reward prediction. Think about the children’s game: “rock, paper, scissors”. In this game, there are three possible win-lose relationships: scissors cuts paper (scissors wins), rock breaks scissors (rock wins), paper covers rock (paper wins). A player’s probability of winning, i.e, reward prediction, is usually 1/2 in a two player game. However, if a player notices that the opponent always shows “scissors” after a round with “paper,” the player’s ability to win might improve, thereby improving his or her reward prediction. Thus, learning an appropriate clue will improve reward prediction.
Previous experiments and/or associated models (TD models) on DA activities have relied exclusively on sensory cues. In our resent study, however, we showed that DA neurons can also use contextual cues in reward prediction. This activity nicely fits with our revised TD model, which can use both contextual and sensory cues in reward prediction. This finding has an interesting implication. Traditionally DA neural activity has been associated more with the functions of reward acquisition and/or motivation, while context-dependent reward prediction, or expectation, has been associated more with the functions of cognition and memory. Our finding suggests a close interplay between these functions, at least partially, through DA neuronal activity.
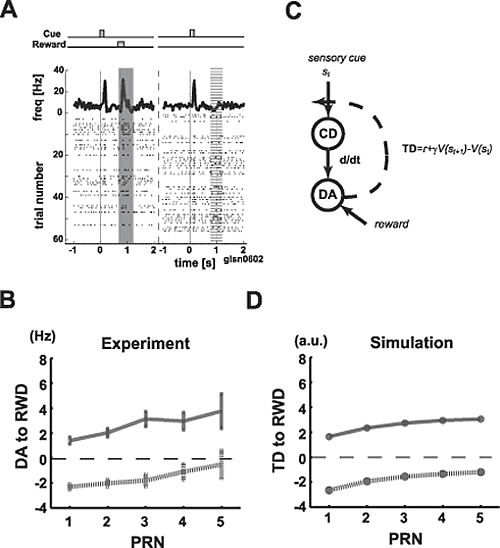
The first experiment was a classic conditioning task. In each trial, a short light stimulus was given to a monkey, followed by a reward with 50% probability (Fig. 1). Therefore, on average, reward prediction is 50%. In actual trials, the reward prediction error was +50% (=100% - 50%) with reward delivery (which is “100%”) and -50% (=0% - 50%) with reward non-delivery (which is “0%”). DA neuron activity qualitatively corresponded with these ±50% error predictions (Fig. 1A). We then plotted DA responses for reward and non-reward trials, separately (Fig. 1B). Here, the horizontal axis indicates the number of non-rewarded trials following the last reward trial (called postreward trial number = PRN). We see positive slopes. In this task, the reward probability is always 50%, regardless of what happened in previous trials, and hence, the reward prediction is also always 50%. Why did we get positive slopes? The TD model can nicely explain this phenomenon (Fig. 1C and D). The TD model, or its hypothesis, postulates that DA activity represents reward prediction error and that learning based on this error occur in each trial, albeit gradually. So, while reward probability trials remains 50% on average, some rewarded or non-rewarded trials can continue during the actual task. Thus, locally, or in these few trials, the reward probability is not exactly 50%. Such a local fluctuation in the reward probability causes fluctuations in learning that are reflected by DA activity.
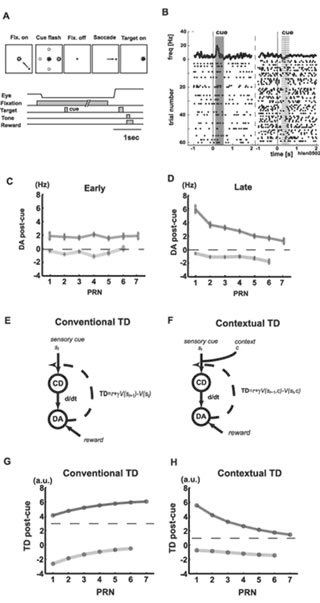
The second experiment was a memory-guided saccadic eye movement task (Fig. 2). In this task, in a trial, one of the four possible target directions was randomly indicated on a screen and the monkey was trained to move its eyes in that direction. A reward was given for only one of the directions in this task. This reward was given only after the monkey’s eye moved correctly towards the indicated direction of the trial. No reward was given for the other three directions, even when the monkey’s eye moved in the indicated direction. On the average, then, reward probability was 25% (Fig. 2A and B). Fig. 2C and D show results. Differences in the activity patterns of early and late stages of the experiment were prominent. Unlike in the first task, there are negative slopes at the late stage of experiment. Why? This task was designed so that the contextual cue, i.e. PRN, affects the reward probability. In other words, although the (ordinary) reward probability was 25%, the reward probability conditional to the PRN changed when the PRN changes. More precisely, the conditional reward probability increased as the PRN increased. With this remark, we make three observations on DA responses. First, the error in the early stage of the experiment seems based on (ordinary) reward probability. Second, error in the late stage seems based on the conditional probability. When PRN was small, the conditional reward probability was lower so that obtaining a reward was more “surprising”, resulting in a larger DA response with PRN being smaller. Third, the monkey learns to predict reward with using PRN over the course of the experiment. To evaluate and confirm these observations, we proposed a contextual TD model, in contrast to conventional ones, and showed that the proposed model can nicely explain observed DA activities (Fig. 2F and H).
Taken together, we found dopamine neuron activity can represent the reward prediction error of predictions based on contextual cues.
