




ある日に彦坂興秀氏(NIH)と私(中原裕之)の二人で眺めた実験結果の図が腑に落ちなくて、いろいろ調べた結果が論文となりました。結果を乱暴に要約すると、“正しいやる気が、学習を促進するとは本当らしい—となります。
ドーパミン神経細胞は、複雑な運動の学習・制御に重要な大脳基底核に豊富に存在します。この細胞が、予測した報酬と実際に獲得できた報酬の違い、「報酬予測誤差」を表す活動を示すことが近年発見されました。この誤差と、強化学習と呼ばれる強力な計算機アルゴリズム(TDモデル)で使用される学習信号の類似性も指摘されました。このドーパミン細胞の活動の解明は、大脳基底核回路の情報処理の解明につながるので、大変注目されています。
実は、ドーパミン細胞の報酬予測誤差と言っても、その詳細は依然不明です。そもそも、報酬予測だっていろいろな予測があります。簡単な例では、じゃんけんに勝つ確率(報酬を得る確率)は、普通は1/2です。これも一つの報酬予測です。一方、もし相手がパーで引き分けた後には必ずチョキを出すと知っていれば、予測は1/2よりも良くなります。このように適切な手がかりを使えれば、予測の精度が向上します。過去の実験・モデルでは、いわば、適切な手がかりを使えない「感覚入力のみに頼るTDモデル」が議論されましたが、今回の結果は、ドーパミン細胞が「文脈を利用できるTDモデル」と対応がつくことを示しました。この結果は、報酬獲得・動機付けなどに近いドーパミン細胞の活動が、認知・記憶などに近い文脈手がかりに基づく報酬予測を利用することを示します。これは、正しいやる気・動機付け・予測が学習に役立つこと、その脳内機構解明に手がかりを与えます。以下、簡単に具体的内容に触れます。
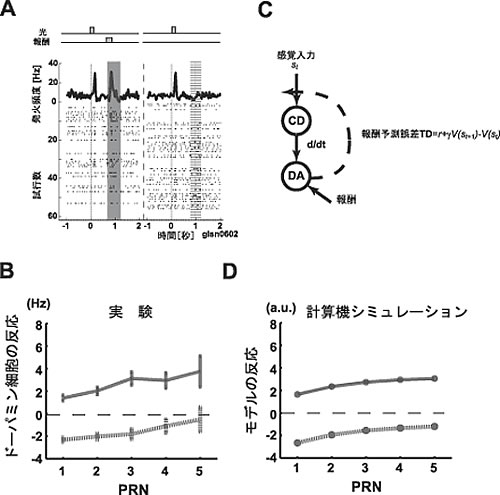
最初の実験課題は、典型的な条件課題です。各試行で、短い光刺激の後、50%の確率でサルは報酬を得ます(図1)。平均としては50%の報酬予測となります。実際の1試行では、報酬をもらえると+50%の報酬予測誤差、もらえないと-50%の誤差となります。この±50%の誤差に対応する活動がドーパミン細胞に見られます(図1A)。次に、報酬のあり・なしの試行を別々に、その試行の直前までに何回の無報酬の試行が続いたかを横軸にしてプロットしました(PRN、図1B)。両方の線が、正の傾きをもっています。直前の試行まで何があろうと、各試行では報酬の確率が50%なので(non- contextual)、いつでも±50%の予測誤差のはずです。なぜでしょう?実は、これは、TDモデル仮説から予想されるのです(図1C、D)。ドーパミン細胞の活動が報酬予測誤差を表し、それを使い、強化学習による学習が各試行で少しずつ進むと考えます。一方、課題では、確かに平均50%の報酬確率でも、実際には、たまたま報酬(あるいは無報酬)の試行が数回続くことはいくらでもあるので、その数回の局所に限ると報酬確率は必ずしも50%ではありません。このような報酬確率の局所的なゆらぎが、学習のゆらぎを起こし、それがドーパミン細胞の活動に現れるのです。要約すると、課題1では、“文脈”が意味をもたない時には「感覚入力のみに頼るTDモデル」が、ドーパミン細胞の活動と、試行のゆらぎを含め、対応がつくことを確認しました。
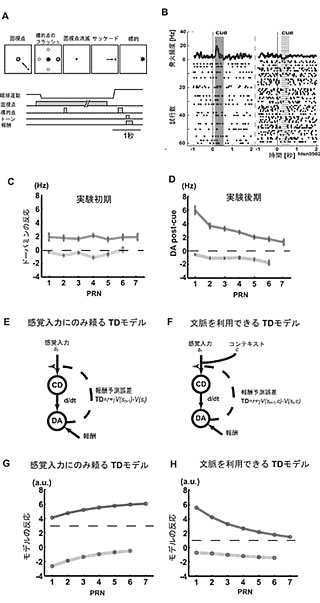
課題2は、記憶誘導性眼球運動課題です(図2)。各試行では、4方向のうち1方向がランダムに指示されて、サルはその方向に眼球運動をします。ただし、たとえ正しく眼球運動したとしても、サルが報酬を実際にもらえるのは4方向のうち1方向のみです。ですので、平均の報酬予測は25%です(図2A、B)。 PRNを使って示したのが図2C、Dです。実験初期と後期で活動のパターンが違います。さらに、後期の傾きは負であり、課題1の傾きと全く逆です。なぜでしょう?実は、この課題ではPRNの数が小さいほど、報酬確率が小さくなるようにしてあります。なので、平均の報酬確率は25%ですが、PRNを手がかりにする報酬確率(条件付確率)が変化します。これから、大雑把に三つのことがわかります。第一に、実験初期はほぼ平均の報酬確率に基く誤差であること、第二に、後期には条件付確率に基づく誤差であること。実際、PRNが小さいと報酬確率が低く、そこで報酬を得ると“より驚き”、より大きい予測誤差を表しています。第三に、手がかりを使う報酬予測は、初期から後期にかけてサルがそのことを学習しています。実際、適切な手がかりを使う「文脈を利用できるTDモデル」を構築すると、実験後期の活動と対応がつくことがわかります(図2F、H)。
まとめると、この両課題を通じ、ドーパミン細胞の活動が適切な手がかりを利用した報酬予測誤差を表すことがわかりました。今後の研究としてさまざまなことがありますが、紙面も尽きたので列挙は差し控えます。
